Pretext is a text measurement library. The most interesting use cases have no DOM at all.
File path middle-truncation
Shipped within days. Paths shrink from the center so you always see the directory root and filename.
Perfect scrollbars
Predict 1,000 variable-height card heights in under 1ms. No estimation, no jumps.
Text without a DOM
Calculate line positions as coordinates. Know the exact texture size before allocating GPU memory.
Zero layout shift
Pre-calculate text heights during SSR. The client hydrates with correct dimensions from the first frame.
Geometry as a unit test
Assert that a 50-character username fits a card. No browser, no screenshots, just arithmetic.
Hundreds of demos, and none of them are the point
Pretext has been public for four days and my timeline looks like a generative art festival. Someone built a dragon that parts text like water. Another rendered fluid smoke as ASCII characters. There are wireframe orbs with text flowing across their surfaces and dual-column magazine layouts that reflow around your cursor in real time. Somebody even made a drum machine out of text. Each one got thousands of likes.
The criticism came just as fast, and it’s fair. Canvas renders pixels, not text. A paragraph drawn on a <canvas> element is invisible to screen readers and can’t be selected or copied. Den Odell wrote on Dev.to that the demo everyone should be paying attention to is the boring one: two function calls that tell you a paragraph is 247px tall without rendering it. A correct number, returned in microseconds, with nothing to screenshot.
He’s right that the canvas demos aren’t the interesting use case. But I think the criticism undersells what’s actually happening, because it’s still framing this as a web thing.
And once you realize that, you start thinking about the environments that never had a browser in the first place: 3D engines, server runtimes, native apps, CI pipelines.
The critics are looking at the wrong demos and the wrong platform.
The 30-year tax on text measurement
If you’ve ever needed to know how tall a paragraph of text is, you’ve probably written some version of this: create an invisible <div>, shove text into it, read the height, throw it away. The browser does the hard part (font metrics, word wrapping, line breaks) and hands you a number. It works fine, exactly once.
Do it 500 times, though, say for a chat message list, and you’ve blocked the main thread for 1.5 seconds. Each measurement costs about 3ms because the browser runs its full layout engine every time: parse the text, consult the font tables, wrap lines, compute geometry, hand back the result.
And it’s actually worse than that, because each call to getBoundingClientRect() or offsetHeight forces a synchronous layout reflow. If your code alternates between writing to the DOM and reading from it (which every virtualization library does), the browser recalculates the entire page geometry on every read. This is layout thrashing, and it’s behind the scrollbar jumps in Slack, the progressive slowdown in long Google Docs, and the stutter in AI chat interfaces when messages stream in faster than the layout engine can keep up.
The frustrating part is that there was never a way around it. Text wrapping depends on font metrics, and font metrics live inside the browser’s layout engine. There’s no public API to ask “how tall would this text be at 300px wide?” without rendering it first.
What Pretext actually does
Cheng Lou released Pretext on March 27, 2026. It’s 15KB of TypeScript with zero dependencies, and it measures multiline text without touching the DOM. The launch tweet crossed 19 million views. The repo passed 18,000 GitHub stars within days. If you’ve used react-motion, you’ve used his work; he also worked on React and ReScript at Meta and is now at Midjourney.
The API is two functions. Seriously, that’s most of it.
prepare() does the expensive work once. It splits the input into segments using Intl.Segmenter (which handles word boundaries for CJK, RTL, emoji, soft hyphens, and the rest of the Unicode menagerie), measures each segment’s width through an offscreen canvas via canvas.measureText(), and caches everything. This costs roughly 19ms for a batch of 500 text blocks.
layout() is the hot path, and it’s almost comically simple. It takes the prepared data, a max width, and a line height, then adds word widths left to right until the sum exceeds the max, breaks the line, and repeats. It returns the total height and line count. This costs 0.09ms for those same 500 texts. That’s not a typo.
import { prepare, layout } from '@chenglou/pretext'
const prepared = prepare(
'AGI 春天到了. بدأت الرحلة 🚀',
'16px Inter'
)
const { height, lineCount } = layout(prepared, 300, 24)
// height: exact pixel height, computed without rendering.The trick is splitting the work. Font measurement (the canvas call) is the expensive part, but it only runs once. After that, layout is pure addition and comparison, so you can rerun it on every window resize, every animation frame, every scroll event. The prepare step already has all the data; layout() is just doing arithmetic on it.
There are a few more functions for when you need finer control. layoutWithLines() returns per-line data (text content, width, cursor positions), and layoutNextLine() is an iterator that lets you vary the width on each line, which is how you flow text around a floated image.
At 0.0002ms per layout call, you can recalculate text positions at 120fps and still have most of your frame budget left for everything else.
Five things you can build now
Perfect virtual scrolling
Every social feed you use (Twitter, Reddit, Discord) does virtual scrolling: only mount the items visible in the viewport, swap them as the user scrolls. The technique is well-understood. The problem nobody has fully solved is height.
When items have different text lengths, the scrollbar needs to know the total height of the list before most items have rendered. Current approaches either measure items offscreen (expensive, causes layout thrashing) or estimate with a fixed average and correct later (produces the jumpy scrollbar everyone hates). You’ve scrolled through a feed and watched the thumb teleport. That’s the estimation correcting itself.
With Pretext, you predict the text height for every item in the list before rendering any of them. A feed of 1,000 variable-height cards gets its heights in under 1ms. The scrollbar is accurate from the first frame, and the list scrolls like a paginated document.
Smart string truncation in code editors
The first production use showed up within days. Fredrika Lindh, an engineer at Cursor, shipped Pretext for file path truncation in Cursor’s diff view. The problem: file paths in monorepos get long. portal-website/apps/web/src/components/background-composer/shared/review-diff-card.test.tsx doesn’t fit in a narrow panel. The old approach is to truncate from the right with an ellipsis, which hides the filename (the part you actually need).
Cursor now truncates from the middle. As the panel narrows, the ellipsis slides inward: at full width you see the complete path, at medium width you get background-com...code-changes-panel.test.tsx, and at narrow width it becomes comp...code-changes-panel.test.tsx. The directory root and the filename stay visible at every width. The truncation point adjusts on every resize.
This requires knowing the pixel width of each segment of the path at the current font and size. DOM measurement would mean a reflow on every resize event. Pretext makes it a layout() call, so the recalculation runs at frame rate without blocking.
The category of problem is broader than file paths. Code editors are full of variable-width strings that need to fit in constrained spaces: breadcrumbs, tab titles, autocomplete suggestions, inline error messages. LLM-generated code is making this worse, producing long single-line strings and verbose inline comments that routinely span hundreds of characters. Anywhere a string needs to shrink gracefully, Pretext replaces a DOM round-trip with arithmetic.
Text in 3D worlds
If you’ve tried putting text into a Three.js scene, you know the options are all bad. Pre-baked texture images are static. SDF font rendering is complex and limited to simple layouts. HTML overlays break immersion and have a performance ceiling. Every option involves guessing at dimensions or over-allocating texture memory.
Pretext calculates line positions as coordinates that map directly onto a CanvasTexture. You know the exact texture dimensions before allocating GPU memory, which is a bigger deal than it sounds because texture memory on a GPU is the kind of resource you don’t want to waste by rounding up.
A simulated monitor in a VR environment, an in-game dialogue system, a 3D dashboard: they all need to answer “how much space does this text occupy?” before drawing a single pixel. Pretext does that with a function call.
Server-side layout prediction
Servers don’t have a DOM, which means every SSR framework (Next.js, Astro, Remix) sends HTML to the client and hopes the layout matches what the developer intended. When it doesn’t, elements jump around during hydration. Google penalizes this as Cumulative Layout Shift, and users notice it as “the page did that annoying thing again.”
Since Pretext runs in Node.js, Deno, and edge functions, a server could pre-calculate the height of every text block during SSR and embed the results as data attributes or CSS custom properties. When the client hydrates, it already knows the dimensions, so nothing shifts.
Any page with dynamic text content (user-generated posts, localized strings, AI-generated responses) has this problem. Pre-calculating on the server makes the first render deterministic.
Geometry as a unit test
This one is my favorite because it’s so obvious in hindsight. Right now, testing whether a UI component overflows its container requires a browser. You spin up Playwright or Cypress, render the page, take a screenshot or read a computed style. It works, but it’s slow and brittle, and a font change on the CI machine can break every test.
If layout is arithmetic, you can unit-test it.
test('long username does not overflow card', () => {
const prepared = prepare('a]'.repeat(50), '14px Inter')
const { height } = layout(prepared, 280, 20)
expect(height).toBeLessThanOrEqual(CARD_MAX_HEIGHT)
})The test runs in milliseconds without a browser and gives you a deterministic answer: does this text fit, or doesn’t it? You can test boundary conditions (Arabic usernames, emoji, 50-character strings) without rendering anything.
This doesn’t replace visual regression testing for style and design. But for geometry questions (does it fit? does it overflow? how many lines?), it’s faster, cheaper, and more reliable than any browser-based approach.
What this means for the platform
There’s a pattern in frontend history where developers get tired of waiting for the platform and just rewrite the thing in userland. React moved DOM reconciliation into JavaScript. Esbuild rewrote bundling in Go. Tailwind moved design decisions into utility classes. Each time, a piece of what the browser (or its toolchain) used to own exclusively got extracted, reimplemented, and often made faster in the process.
Pretext does this for text measurement. And the interesting implication isn’t the speed; it’s the portability. Once layout calculation lives in JavaScript, it runs anywhere JavaScript runs. The same logic that sizes a chat bubble in React can size a text panel in Three.js or a notification on an edge server.
There is an honest trade-off here, though. Pretext has to stay in sync with browser font rendering across versions, platforms, and edge cases, and that is genuinely hard. Cheng Lou tested against the full text of The Great Gatsby and public domain texts in Thai, Chinese, Korean, Japanese, and Arabic. Firefox on Linux still had edge-case issues at launch. Maintaining parity with the browser’s font engine is ongoing work, not a problem you solve and forget.
The W3C’s CSS Houdini group has a FontMetrics API draft that would give developers native access to the information Pretext extracts through canvas, but the spec has sat in Editor’s Draft status with no browser implementing it. Pretext fills that gap with a shim small enough to fit in a tweet.
One more thing I find genuinely interesting about how this was built: Cheng Lou used Claude Code and OpenAI Codex to iterate the implementation against browser ground-truth measurements across container widths for weeks. So the library is an artifact of AI-assisted development, built to accelerate the kinds of UIs that AI tools themselves produce (chat interfaces, streaming text, long-form code generation). The toolchain is eating its own tail in the best possible way.
Where someone could take this next
The layout() function is pure arithmetic. There’s no DOM, no Canvas, no browser API in the hot path. It’s just addition and comparison, which means it could compile to WASM and run in Rust, Go, Swift, or anything else with a WASM runtime. In principle, the layout engine is already portable.
The catch is prepare(). The initial measurement step depends on canvas.measureText(), which delegates to the browser’s font engine. To run that outside a browser, you’d need a font rasterizer (FreeType, HarfBuzz, something like that) whose metrics match Chrome’s pixel-for-pixel. That’s harder than it sounds; Cheng Lou spent weeks calibrating against browser ground truth because font metrics diverge across platforms, scripts, and rendering engines. A WASM port of the measurement layer that stays pixel-accurate across fonts and languages is a real project, not a weekend wrapper.
There’s an obvious middle ground, though: run prepare() once in a JS environment with Canvas access, serialize the width data, then ship that serialized payload to a WASM layout engine that runs wherever. The measurement happens once; the layout runs N times in whatever runtime you want. This split already mirrors how Pretext works internally. Someone just needs to formalize the serialization boundary.
I’ve been thinking about a related concept I’m calling pretext-predict, which is about predicting full UI component dimensions, not just text. Imagine a JSON schema that describes a card’s padding, gaps, conditional children, and aspect-ratio boxes, with Pretext handling the text measurement underneath. You could get the height of a complete feed item without rendering anything. The math is trivial (total height equals components plus gaps plus padding). The hard part is the combinatorics of conditional layouts and nested containers, and knowing when you’ve reimplemented enough of a layout engine that you should have just used one.
The 30-year assumption that text measurement requires rendering is broken. The question that matters now is what developers build when measurement is free.
Updates
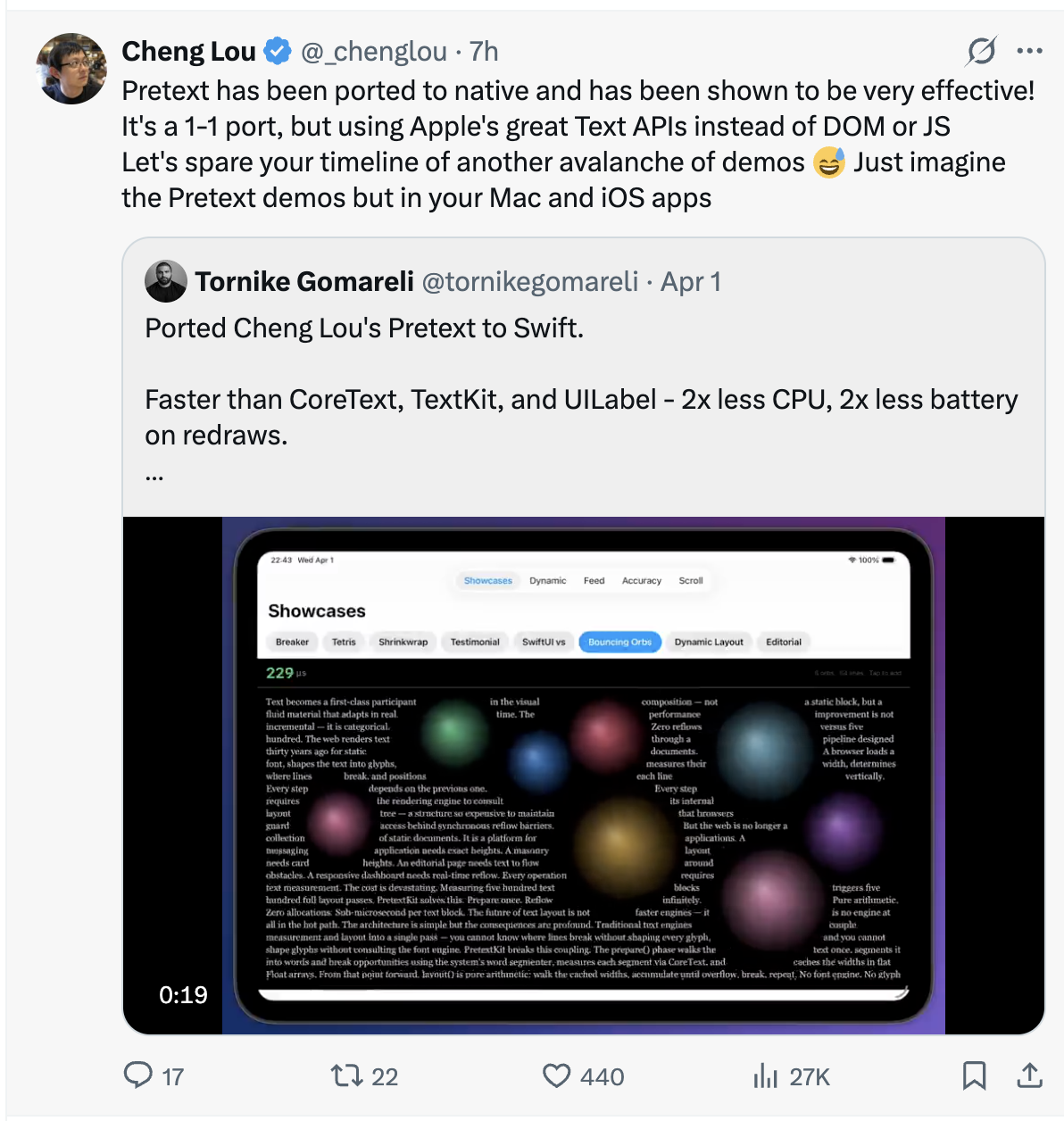
April 1, 2026. Tornike Gomareli released swift-pretextkit, a native Swift port. It uses Apple’s CoreText for the prepare() step instead of canvas, and Gomareli’s benchmarks show it beating CoreText, TextKit, and UILabel directly: 2x less CPU, 2x less battery on redraws. Cheng Lou confirmed it’s a 1-to-1 port. Five days from launch to the first non-JavaScript runtime.